Belajar Distribusi Normal
Distribusi normal adalah distribusi probabilitas yang penting dalam statistik karena banyak fenomena alam mengikuti pola distribusi ini. Distribusi normal juga dikenal sebagai Distribusi Gaussian dan Kurva Lonceng.
Distribusi normal adalah fungsi probabilitas yang menggambarkan bagaimana nilai suatu variabel didistribusikan. Ini adalah distribusi simetris di mana sebagian besar pengamatan mengelompok di sekitar pusat puncak dan probabilitas untuk nilai yang lebih jauh dari nilai rata-rata tersebar secara merata di kedua arah.
Parameter Distribusi Normal
Seperti halnya distribusi probabilitas lainnya, parameter untuk distribusi normal menentukan bentuk dan probabilitasnya secara keseluruhan. Distribusi normal memiliki dua parameter, nilai rata-rata dan simpangan baku/deviasi standar. Distribusi normal tidak hanya memiliki satu bentuk. Sebaliknya, bentuk berubah berdasarkan nilai parameternya.
Rata-rata
Rata-rata atau mean adalah kecenderungan dari distribusi untuk menyebar secara terpusat. Nilai rata-rata menentukan lokasi puncak untuk distribusi normal. Sebagian besar nilai mengelompok di sekitar mean. Pada grafik, mengubah mean akan menggeser seluruh kurva ke kiri atau kanan pada sumbu X.
Deviasi standar
Deviasi standar adalah ukuran variabilitas. Ini mendefinisikan lebar distribusi normal. Standar deviasi menentukan seberapa jauh nilai rata-rata cenderung turun. Ini mewakili jarak yang khas antara pengamatan dan rata-rata.
Pada grafik, mengubah simpangan baku akan mempersempit atau menyebarkan lebar distribusi di sepanjang sumbu X. Standar deviasi yang lebih besar menghasilkan distribusi yang lebih tersebar.
Parameter populasi versus perkiraan sampel
Rata-rata dan deviasi standar adalah nilai parameter yang berlaku untuk seluruh populasi. Untuk distribusi normal, ahli statistik menggunakan simbol Yunani μ (mu) untuk mean populasi dan σ (sigma) untuk deviasi standar populasi.
Namun, parameter populasi biasanya tidak diketahui, karena secara umum tidak mungkin untuk mengukur seluruh populasi. Namun, sampel acak untuk menghitung estimasi parameter ini dapat digunakan. Ahli statistik merepresentasikan estimasi sampel dari parameter ini menggunakan x̅ untuk mean sampel dan s untuk deviasi standar sampel.
Karakteristik Umum Distribusi Normal
Meskipun bentuknya berbeda, semua bentuk distribusi normal memiliki sifat karakteristik sebagai berikut.
- Kedua sisinya simetris.
- Mean, median, dan mode biasanya bernilai sama.
- Separuh dari populasi lebih kecil dari mean dan separuh lainnya lebih besar dari mean.
- Aturan empiris memberikan proporsi nilai yang berada dalam jarak tertentu dari mean.
Aturan Empiris Distribusi Normal
Deviasi standar dapat digunakan untuk menentukan proporsi nilai yang masuk dalam deviasi standar tertentu dari rata-rata. Misalnya, dalam distribusi normal, 68% pengamatan berada dalam kisaran +/- 1 standar deviasi dari rata-rata, 95% berada dalam kisaran +/- 2 standar deviasi dan 99,7% berada dalam kisaran +/- 3 standar deviasi dari rata-rata. Karakteristik ini adalah bagian dari Aturan Empiris, yang menjelaskan persentase data yang termasuk dalam jumlah tertentu deviasi standar dari mean untuk kurva berbentuk lonceng. Berikut adalah distribusi normal dengan nilai rata-rata 2 dan simpangan baku 10.

Distribusi Normal Standar dan Skor Z
Seperti terlihat di atas, distribusi normal memiliki bentuk berbeda pada nilai parameternya. Namun, distribusi normal standar adalah kasus khusus dari distribusi normal di mana meannya nol. Distribusi ini juga dikenal sebagai distribusi Z.
Nilai pada distribusi normal standar dikenal sebagai skor standar atau skor Z. Skor standar mewakili jumlah deviasi standar di atas atau di bawah rata-rata observasi tertentu. Misalnya, skor standar 1,5 menunjukkan bahwa observasi adalah 1,5 deviasi standar di atas mean. Di sisi lain, skor negatif mewakili nilai di bawah rata-rata. Rata-rata memiliki skor Z = 0.
Standardisasi: Cara Menghitung Nilai Z
Skor standar adalah cara yang bagus untuk memahami di mana pengamatan tertentu berada relatif terhadap keseluruhan distribusi. Proses standardisasi memungkinkan untuk membandingkan pengamatan dan menghitung probabilitas di berbagai populasi.
Untuk menstandarkan data, kita perlu mengubah pengukuran mentah menjadi skor-Z.
Untuk menghitung skor standar observasi, ambil ukuran mentahnya, kurangi rata-ratanya, dan bagi dengan deviasi standar. Secara matematis, rumus untuk proses tersebut adalah sebagai berikut:
Z = (X−μ)/σ
X mewakili nilai mentah dari pengukuran yang diinginkan. μ dan sigma mewakili parameter untuk rata-rata dan simpangan baku populasi tempat observasi diambil.
Skor Standar untuk Perbandingan Tinggi Badan Laki-laki dan Perempuan
Misalkan kita ingin membandingkan tinggi badan pelajar pria dengan pelajar wanita.Misalnya kita bandingkan seorang pria dengan tinggi rata-rata 170 cm dan wanita 165 cm.
Jika kita membandingkan nilai-nilai mentahnya, mudah untuk melihat bahwa pria lebih tinggi daripada wanita. Namun, mari kita bandingkan skor standar mereka.
Untuk melakukan ini, kita perlu mengetahui distribusi untuk tinggi pria dan wanita. Asumsikan tinggi badan pria dan wanita mengikuti distribusi normal dengan nilai parameter berikut:
Tinggi manusia 𝑚𝑢 = 175 𝑠𝑖𝑔𝑚𝑎 = 30 Tinggi wanita 𝑚𝑢 = 160 𝑠𝑖𝑔𝑚𝑎 a = 10
Sekarang kita akan menghitung skor Z:
Pria = (170–175)/30
Wanita = (165–160)/10
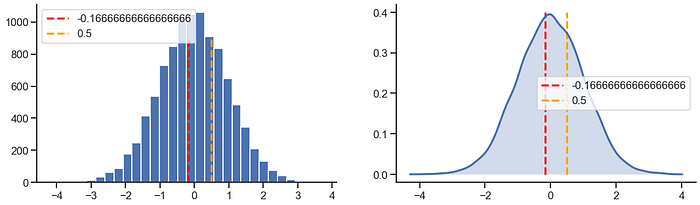
Z skor pria = (170–175)/30 = -0.167
Z skor wanita = (165–160)/10 = 0.5
Z-score untuk pria (-0.1667), yang berarti pria sampel memiliki tinggi lebih kecil dari rata-rata pria. Di sisi lain, wanita memiliki Z-score yang positif (0.5). Hal ini berarti tinggi wanita sampel lebih tinggi dari rata-rata. Nilai Z ini dapat digambarkan dalam distribusi normal standar di bawah ini.
Menemukan Area di Bawah Kurva Distribusi Normal
Distribusi normal, seperti halnya distribusi probabilitas lainnya, proporsi area yang berada di bawah kurva antara dua titik pada plot distribusi probabilitas menunjukkan probabilitas suatu nilai akan jatuh dalam interval itu.
Biasanya, kita menggunakan perangkat lunak statistik untuk mencari area di bawah kurva. Namun, saat Anda bekerja dengan distribusi normal dan mengonversi nilai menjadi skor standar, kita dapat menghitung area dengan mencari Z-skor dalam Tabel Distribusi Normal Standar.
mean=0
std=1
x_min = mean-(3*std)
x_max = mean+(3*std)
x = np.linspace(x_min, x_max, 100)
y = stats.norm.pdf(x,mean,std)
plt.plot(x,y, color=’black’)
def normal_distribution_function(x):
value = stats.norm.pdf(x,mean,std)
return value
x1 = x_min
x2 = (110–100)/15
res, err = quad(normal_distribution_function, x1, x2)
print(‘Distribusi Normal (mean,std):’,mean,std)
print(‘Integrasi kurva antara {} and {} → ‘.format(x1,x2),res)
ptx = np.linspace(x1, x2, 100)
pty = stats.norm.pdf(ptx,mean,std)
plt.fill_between(ptx, pty, color=’#0b559f’, alpha=0.5)
plt.xlim(x_min,x_max)
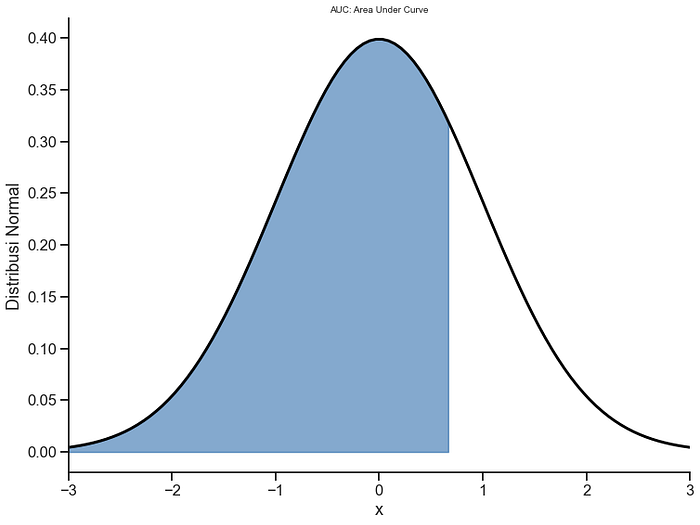
plt.title(‘AUC: Area Under Curve’,fontsize=10)
plt.xlabel(‘x’)
plt.ylabel(‘Distribusi Normal’)
sns.despine()
Distribusi Normal (mean,std): 0 1 Integrasi kurva antara -3 and 0.6666666666666666 → 0.746157564421447
Alasan Pentingnya Distribusi Normal
Ada beberapa alasan mengapa distribusi normal sangat penting dalam statistik.
- Beberapa uji hipotesis statistik mengasumsikan bahwa data mengikuti distribusi normal.
- Regresi linier dan nonlinier keduanya mengasumsikan bahwa residual mengikuti distribusi normal.
- Teorema batas pusat menyatakan bahwa ketika ukuran sampel meningkat, distribusi sampling dari rata-rata mengikuti distribusi normal bahkan ketika distribusi yang mendasari variabel aslinya tidak normal.
Baca juga: Belajar Uji Normalitas Suatu Distribusi di https://van-plaosan.medium.com/belajar-uji-normalitas-suatu-distribusi-dd1180ee6ecf
